Getting started with Kafka Streams
![]()
Kafka Streams is a Java library and framework for creating applications that consume, process, and return Apache Kafka messages. It’s conceptually similar to Apache Camel, but tightly coupled to Kafka, and optimized for the kinds of operations that Kakfa clients typically do. Kafka Streams is therefore less flexible than Camel, but probably makes it easier to do Kafka-related things. Camel has a Kafka client of its own, so an alternative to Kafka Streams would be to write a Camel application with Kafka producers and consumers.
Note
There’s no need to understand Camel to follow this article. However, because Camel and Kafka Streams have broadly similar applications, I’ll point out similarities and differences from time to time.
In this article I describe step-by-step how to deploy and run a trivial Kafka Streams application, from the ground up. I’ll use nothing but command-line tools and a text editor so, I hope, it’s clear what’s going on.
The article is a somewhat expanded version of the first step of the
official Kafka Streams tutorial, and begins with the same
Pipe.java applcation. It then expands this application to
do some simple data processing. All the Pipe application does is copy
from one Kafka topic to another. This is shown conceptually in the
diagram below.
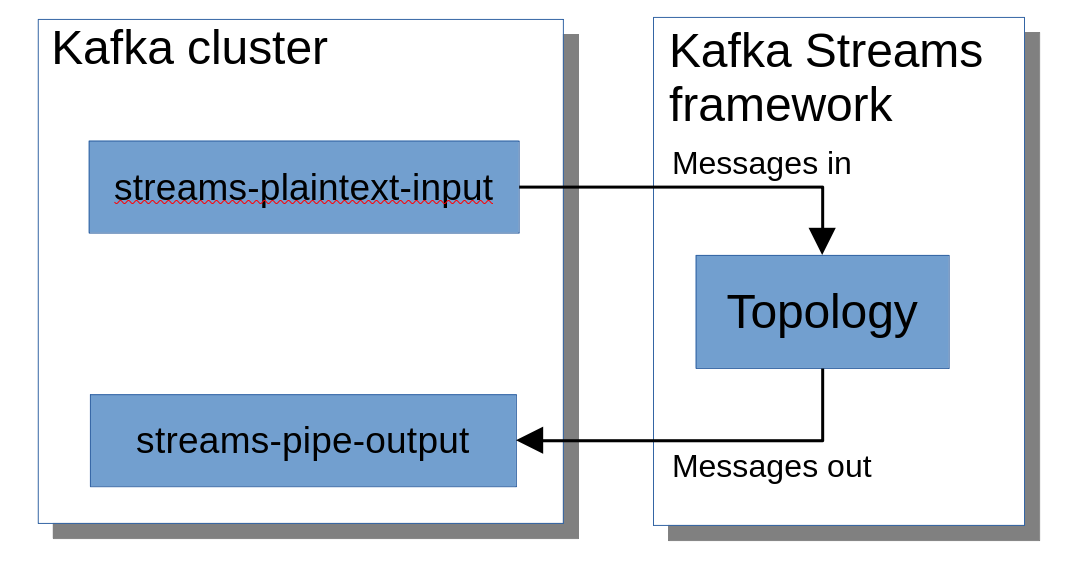
I’ll explain what a ‘topology’ is shortly.
Anatomy of a simple Kafka Streams application
Note
With a few exceptions, which I hope are obvious, when I don’t give package names for Java classes, they are in the packageorg.apache.kafka.streams.
Running a basic Kafka Streams applications amounts to instantiating
KafkaStreams object, and calling start() on it. The
start method will not exit until something in the
application causes it to stop.
The sequence of processing steps that the application performs is called, in Kafka Streams jargon, a ‘topology’. A Streams topology is broadly similar to a Camel ‘context’ with a single ‘route’.
So if we have defined a toplogy, coding a basic Streams application looks like this:
Topology topology = ...
Properties props = new Properties();
props.put(StreamsConfig.APPLICATION_ID_CONFIG, "streams-pipe");
props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
// Set other properties...
KafkaStreams streams = new KafkaStreams (topology, props);
streams.start();There are many properties that might need to be set, but in almost all cases you’ll need to set the application ID and the bootstrap server – this, of course, identifies the Kafka broker(s) the application will make first contact with.
The interesting part of programming Kafka Streams is defining the toplogy. More on that later, once we’ve set everything up.
Prerequisites
In this article I assume that the reader has a working Kafka
installation. It doesn’t matter whether it’s a simple, local
installation with one broker, or a complex deployment with multiple
brokers in the cloud. However, I’m assuming that you have a way to run
the usual command-line utilities like
kafka-console-producer.sh. If you’re running a Linux
installation, you probably just need to
cd /opt/kafkaor wherever the installation is. In a Kubernetes environment you’ll probably have to log into a running Kafka broker pod to get to the necessary binaries, or install Kafka locally as well.
In any case, in the commands in this article, I assume that Kafka is running on my development workstation and, where I need a Kafka bootstrap address, it will always be localhost:9092.
To follow this example (and any of the official Kafka tutorials)
you’ll need Maven, or an IDE tool that can understand Maven
pom.xml files. Of course you’ll need a Java compiler –
anything from Java 1.8 onwards should work fine.
Installing the sample application
Kafka provides a Maven archetype for constructing a trivial Kafka Streams application. Use the archetype like this:
mvn archetype:generate \
-DarchetypeGroupId=org.apache.kafka \
-DarchetypeArtifactId=streams-quickstart-java \
-DarchetypeVersion=3.6.1 \
-DgroupId=me.kevinboone.apacheintegration \
-DartifactId=kstreams_test \
-Dversion=0.1 \
-Dpackage=me.kevinboone.apacheintegration.kstreams_testI’ve used my own names here; of course you can use any names you
like. In this example, the application will be installed into the
directory kstreams_test.
The generated code will include a Maven pom.xml, some
logging configuration, and a few Java sources. We will be working with
Pipe.java which, if you ran the Maven archetype as I did,
will be in
src/main/java/me/kevinboone/apacheintegration/kstreams_testOther than Pipe.java and pom.xml, none of
the other files generated by the archetype are relevant in this
example.
Important: If you aren’t using Eclipse, edit the generated
pom.xml and comment out the configuration for the Eclipse
JDT compiler:
<!--compilerId>jdt</compilerId-->If you look at pom.xml, you’ll see the only dependency
needed for a basic Kafka Streams application:
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-streams</artifactId>
<version>${kafka.version}</version>
</dependency>
Of course, this package has many sub-dependencies, including the ordinary Kafka Java client.
Note
The version of the Kafka Streams library need not be the same as that of the Kafka installation itself. Of course, there are advantages to assuming that you use the latest versions of both.
Setting up Kafka
The documentation is clear that Kafka topics used by a streams application must be created administratively. The explanation given is that topics might be shared between multiple applications, which might make different assumptions about their structure. This is true of non-Streams applications as well but, whether the explanation is convincing, a Kafka Streams application will not auto-create topics even if Kafka is set up to allow it.
So we’ll need to create the topics that the sample application uses:
bin/kafka-topics.sh --create \
--bootstrap-server localhost:9092 \
--replication-factor 1 \
--partitions 1 \
--topic streams-plaintext-input
bin/kafka-topics.sh --create \
--bootstrap-server localhost:9092 \
--replication-factor 1 \
--partitions 1 \
--topic streams-pipe-output Looking at the topology
The Pipe application defines its topology like this:
StreamsBuilder builder = new StreamsBuilder();
builder.stream("streams-plaintext-input")
.to("streams-pipe-output");
Topology topology = builder.build();This is an example of what has become known as the “fluent builder” pattern – each method call on the ‘builder’ object returns another builder object which can have other methods called on it. So the specification of the topology amounts to a chain of method calls. This will become clearer, if it is not already, with more complex examples.
Note Apache Camel also provides a ‘fluent builder’ method for defining Camel routes. Unlike Camel, however, a Streams topology can’t have multiple
to(...)elements. Streams can send messages to multiple targets, but not like that.
First run
We’ll need a Kafka producer and consumer to see the application doing
anything. We’ll send messages to the topic
streams-plaintext-input, and consume them from
streams-pipe-output. The application should pipe messages
from the one topic to the other.
A simple way to send and receive messages is to run the simple Kafka console tools in two different sessions:
./bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic streams-pipe-output./bin/kafka-console-producer.sh --bootstrap-server localhost:9092 --topic streams-plaintext-inputI run the Pipe application like this:
mvn compile exec:java -Dexec.mainClass=me.kevinboone.apacheintegration.kstreams_test.PipeWith the application running, anything typed into the message producer utility should appear at the message consumer. If it does, well done, the Streams application is working.
Adding a simple transformation
Let’s extend the trivial Streams topology to performa a simple transformation – converting textual input to lower case.
Change the line
builder.stream("streams-plaintext-input")...to:
builder.stream ("streams-plaintext-input")
.mapValues (value->((String)value).toLowerCase())
.to ("streams-pipe-output");We’ve inserted a call to mapValues() between the message
consumptin and production.
mapValues is a method that is defined to take one
parameter, which implements the ValueMapper interface. This
interface has one method, that takes one argument and returns one return
value. The lamda expression
value->((String)value).toLowerCase()satisfies this interface, because it implicitly defines a method with one parameter and one return value.
Note
mapValues()is broadly similar to Camel’sprocess(). However, Kafka Streams also has aprocess()method with a slightly different purpose.
In short, mapValues() provides a Kafka message body to
an expression, and sets the new message body to the result of the
expression.
Note
The Kafka Streams API relies heavily on generic types and lambda expressions. If you’re not familiar with how these work in Java, it might be worth brushing up before digging into Kafka Streams beyond the ‘Hello, World’ level.
When you run this example, and messages sent to
streams-plaintext-input should appear on
streams-pipe-output in only lower case.
Note
Kafka messages form key-value pairs. This example does not transform, or even see, message keys. There is amap()method that operates on keys, as well as message bodies.
Adding some simple logging
Perhaps we want to trace the way that a message is transformed in the
execution of a topology. To do that, we’ll need to ‘see’ the message
body, but not change it. We can use the peek() method for
that.
builder.stream ("streams-plaintext-input")
.peek ((key,value)->System.out.println ("before: " + value))
.mapValues (value->((String)value).toLowerCase())
.peek ((key,value)->System.out.println ("after: " + value))
.to ("streams-pipe-output");The peek() method takes a paramter of type
ForeachAction, which is an interface that specifies a
single method that takes two values, and returns nothing
(void). To satisfy this interface, our lambda expression
must take two arguments:
.peek ((key,value)->...)and call a method which returns void (as
println() does).
In this case, I’m only displaying the message body, so I don’t need
the key argument; but it has to be present, even if only as
a placeholder, or the lambda expression won’t match the interface.
Because the interface method is defined to return void,
the right-hand side of the lambda’s -> must be a method
call that is defined to return void as well. So the
peek() method does not allow an expression that modifies
the key or the value.
When you run this example, you should see some logging output from the application, something like this:
before: Hello, World!
after: hello, world!Duplicating and filtering the message stream
In this section I’ll describe some simple message processing operations that could be added to the basic Streams application.
Note
I’m not giving explicit instructions on running these examples: the changes are in the same part of the code as all those above and, I hope, the results will be reasonably clear.
If we want to duplicate a message to multiple topics, we can’t do this:
builder.stream ("input")
.to ("output1")
.to ("output2");The to() method is terminal in the fluent builder – it
doesn’t return anything we can call further methods on. This is,
perhaps, a little disconcerting to Camel programmers, because the Camel
builder does allow it.
We can, however, do this, which has the same effect:
KStream ks = builder.stream("streams-plaintext-input");
ks.to("streams-pipe-output");
ks.to("streams-pipe-output-long");This topology defintion will take the input from
streams-plaintext-input and send it to both
streams-pipe-output and
streams-pipe-output-long. The reason for the
-long naming should become clear shortly.
Note
It won’t always matter, but it’s worth bearing in mind that this method of splitting the stream duplicates the message keys as well as the values.
Rather than a straight duplication, we can filter the messages, so
that some go to one topic, and some to others. In the example below,
messages whose bodies are ten characters in length or shorter go to
streams-pipe-output-long, while others go to
streams-pipe-output.
KStream<String,String> ks = builder.stream("streams-plaintext-input");
ks.filter((key,value)->(value.length() <= 10).to ("streams-pipe-output");
ks.filter((key,value)->(value.length() > 10).to ("streams-pipe-output-long");The filter() method takes a lambda expression that
evaluates to a boolean value – true to forward the message,
false to drop it.
When it comes to dynamic routing, that is, routing messages to topics whose names are determined at runtime, it’s easy to make the same mistake that Camel developers often make.
Suppose I want to route messages to a topic whose name depends on
(say) the current date. I have a method getDateString()
that returns the date in a suitable format. It’s tempting to write
something like this:
KStream<String,String> ks = builder.stream("streams-plaintext-input");
.to ("streams-pipe-output_" + getDateString());This fails, for reasons that are not obvious. The reason it fails is
that the fluent builder pattern creates a topology only once. It may
well executes for the life of the application, but all the data it needs
to execute has to be provided at start-up time. The
getDateString() method will be executed only once and,
though the date changes, the argument to the to() was
evaluated only once.
Kafka Streams has a way around this problem (as Camel does). Rather
than initializing the to() method with a string, we
initialize it with a TopicExtractor. In practice, it seems
to be common to use a lambda expression to do this, rather than writing
a class that implements the TopicExtractor interface
explicitly. So we could do this:
KStream<String,String> ks = builder.stream("streams-plaintext-input");
.to ((key, value, context)->"streams-pipe-output_" + getDateString());The lamba expression (which results in a specific method call on a
TopicExtractor) is executed for each message, not just at
start-up.
KStream<String,String> ks = builder.stream("streams-plaintext-input");
ks.split()
.branch ( (key,value)->(value.length() > 10),
Branched.withConsumer
(stream->stream.to ("streams-pipe-output-long")) )
.defaultBranch (
Branched.withConsumer
(stream->stream.to ("streams-pipe-output")) );Closing remarks
It’s probably not a surprise that this article only scratches the surface of the Kafka Streams API, which is extensive. on stateful operations, stream merging, partition and key management, error handling, etc., etc. place to start. In Part 2 I’ll tackle the first of these – the stateful operations of counting and aggregation.
Have you posted something in response to this page?
Feel free to send a webmention
to notify me, giving the URL of the blog or page that refers to
this one.

