Command-line hacking: displaying a weather summary
 This is the first in what I hope will become a series of
articles on doing off-beat and (I hope) interesting things
with standard Linux command-line tools. In this post
I'll give some ideas on retrieving a weather forecast summary
from the BBC's RSS feed, and formatting it nicely.
The idea is that you can just type, for example,
This is the first in what I hope will become a series of
articles on doing off-beat and (I hope) interesting things
with standard Linux command-line tools. In this post
I'll give some ideas on retrieving a weather forecast summary
from the BBC's RSS feed, and formatting it nicely.
The idea is that you can just type, for example,
weather at the prompt, and see a daily weather
summary.
The basic strategy will be use curl to retrieve the
weather forecast in RSS (XML) format, xmllint to
extract the relevant parts of the document, sed to
convert the text into groff format, then finally
groff to format it, adding colour and emphasis.
groff is highly configurable and
produces nicely left- and right-justified text. It's easy to
change this layout if required.
A quick-and-dirty alternative to using groff would be
to use fmt, and then use sed to insert
terminal escape codes to add the emphasis and colour. But this
isn't very elegant.
Disclaimer: I don't claim that the way I go about solving this problem is the only way, or even the best. There are many ways to solve the same problem with shell scripting.
Prerequisites
To follow this example, you'll need curl and groff
(which are part of the base distribution for many Linux variants)
and xmllint (which probably isn't). On Ubuntu and similar,
you can get
xmllint by running:
$ sudo apt-get install libxml2-utils
Background
The basic URL for the BBC's 3-day forecast, in RSS format, is:
https://weather-broker-cdn.api.bbci.co.uk/en/forecast/rss/3day/NNNNNN
NNNNNN is a numeric code for the location. So far
as I know, there is no published list of these location codes, and they
don't correspond (to the best of my knowledge) to any geographic
indicator. You can
find the code for your location by looking at
the BBC weather site and searching for the relevant name.
The numeric code will appear in the URL. In the examples that follow,
I'll be using the code for London, which is 2643743.
The following command will request the 3-day weather forecast for London, and dump it to standard out:
$ curl https://weather-broker-cdn.api.bbci.co.uk/en/forecast/rss/3day/2643743
If you examine the output, you'll see the following basic structure:
<rss ...>
<channel ...>
<item>
<title>Today: Light Cloud...</title>
<description>Visibility: Good...</description>
...
</item>
<item>
<title>Friday: Heavy Cloud...</title>
<description>Visibility: Poor...</description>
...
</item>
...
All RSS files are XML with this same layout -- only the content differs. In this case, there are three <item> elements, one for each day of the forecast. Each item has a title and a description which, to some extent, are pre-formatted display. Depending on the application, it might be sufficient to display only the "title" element -- the description is a bit wordy. Note that the title and description are intended to be displayed as provided. They do benefit from being formatted, though, and in my example I've added some text highlighting; still, it isn't easy actually to parse these text strings. Apart from anything else, the format tends to change, and relying on a particular entry (e.g., "Visibility") being present is a bad idea.
So our task here is to parse the XML, extract the title (and perhaps description), and format the results for display in the terminal. Here's what I'm aiming for:
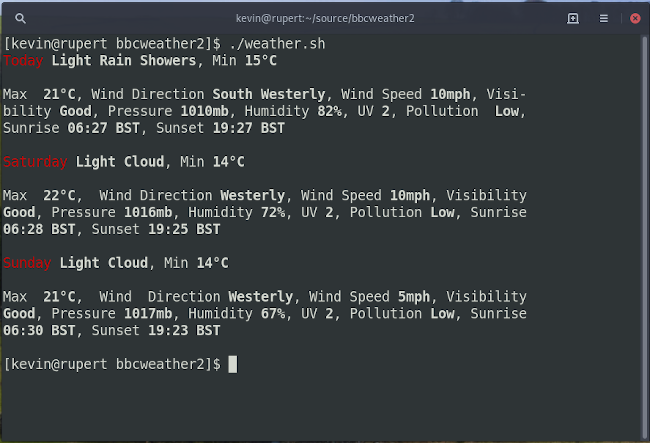
Parsing the XML
It would be nice to be able to extract the relevant parts of
the XML file using simple command-line utilities like grep
and sed. Since the structure of the BBC's RSS is so
regular, that's almost possible. We could, for example,
just grep for lines that contain "title" and
"description".
Unfortunately, there are other lines in the XML that contain these tags. Since they tend to occur in the same position, a quick-and-dirty hack would be to extract specific occurences by their position in the XML. However, this isn't very robust -- and remember that we're working with a file format that is not documented, and whose layout could change. We need to ensure that, so long as we get a valid RSS document, we can display something useful. Consequently, it's necessary to do real XML parsing to extract the data.
The xmllint utility makes this easy, so long as
the parsing is not too complex. In this case we just want to
extract certain elements, that have well-defined positions in
the XML's tree structure. This will do the trick:
curl -s [BBC URL] \ | xmllint --xpath rss/channel/item/title\|rss/channel/item/description
The --xpath switch takes one or more paths, separated
by a vertical bar (pipe). Be careful to prevent the shell treating the
pipe as an instruction to perform a pipe operation: here I've
escaped it with a backslash but, of course, there are other ways.
Note:
RSS XML files are usually encoded in UTF-8 format. This is a multi-byte text encoding, whose significance will become apparent later.
Converting the XML
The first task is to strip any remaining XML tags from the text. That's easy
to do with sed
| sed -e 's/<[^>]*>//g'
sed operates on standard input, and outputs to standard output. It
edits the text stream in accordance with the instructions provided on the
command line. In this case, I'm using the s/search/replace/g
instruction, which replaces all instances ('g' for 'global') of the
pattern with "//" -- that is, nothing. The pattern is a regular expression;
in this case it matches anything starting with "<" and ending in ">",
except for the ">" symbol itself.
sed's pattern matching is "greedy" by default -- that is,
it will match the longest sequence of characters that it can.
This is why we need the slightly odd pattern described above, and it's a
format that I'll be using repeatedly in this example. We only want to match
the XML tags -- we don't want to match from the start of one tag, right to
the end of the next, which is what will happen if we're not careful.
xmllint won't insert any blank lines between the XML sections it
extracts. The
text of the BBC weather feed contains no line breaks of its own, but we will
need to break the lines later so they fit nicely on the screen. But first,
we need to insert our own line breaks between each day's weather forecast,
forming a blank line. That is, each days's forecast will be followed by a blank
line. If we don't do that, when we format the text using groff, it
will want to merge all the lines together, and then format the whole chunk.
To change a line break into a blank line, I'm doing this:
| tr '\n' '#' \ | sed -e 's/#/\n\n/g' \
sed won't easily match on, or convert, end-of-line marks. So, instead
I'm using tr to translate these into hash (#) characters, and
then sed to translate these into pairs of newlines. Of course,
this won't work if the text actually contains hash characters of its own --
you'd have to pick a different symbol.
My personal preference is to remove the Fahrenheit temperatures that the BBC feed provides, and just keep the Celcius. Your preference may differ, of course. The Fahrenheit temperatures appear in brackets: "(38°F)". To remove these:
| sed -e 's/ (.*F)//g' \
Again, I know that this pattern doesn't appear anywhere else in the text, so
it's safe to match it this way. Note that I'm removing the extra space
that appears in front of the opening bracket but, in fact,
groff will do that later, anyway.
In my script I carry out a number of other simple transformations: shortening
long words, that kind of thing. I'm not going to describe these in detail
because they just use the same application of sed as the
previous steps..
However, there are a few things that merit explanation.
In my script, I display the names of the days (which include "Today" and
"Tonight") in red, to make the sections of the output easier to distinguish.
Since
I'll be processing the text with groff, I want to surround these
words with groff colour codes. These are a bit arcance but,
essentially, we need \m[name] to set the colour, followed by
\m[] to set it back to the default.
My way of making this change isn't very elegant:
| sed -e 's/Tonight\|Today\|Monday\|Tuesday\|Wednesday\ \|Thursday\|Friday\|Saturday\|Sunday/\\m[red]\0\\m[]/g' \
Since the day name is always the first token on a line, there ought to be a more elegant way to match it. However, it isn't the first token on every line. All the other ways I found to match this text were no less ugly, so I'm keeping what I have until somebody suggests a better way.
Note that in the replacement text, \0 means "substitute the
text that matched". Because the backslash character has a specific meaning
to sed, when we want an actual backslash in the output, we have
to write \\. It's this kind of fiddly that makes text-processing
scripts so unreadable, but there isn't really an alternative.
Incidentally, sed can take multiple operations on the same
command line. They are separated by semicolons. This is quicker, but
a sed command with dozens of operations on the same line is
profoundly unreadable (rather than just very unreadable).
So I've used sequential invocations of sed
with one operation each.
I've used a similar technique as the above to add other kinds of emphasis.
To make text bold, for example, we surround it by the groff
codes \fB and \fR ("format bold" and "format regular").
Again, we need to be careful about escaping the backslashes when
writing these codes in a script.
Formatting the text
Finally, we're (almost) ready to pass the converted text, with its embedded formatting
codes, to groff. First, though, we need to add a recognizable
character or character sequence to the start of each blank line.
I'm using "###", but anything that we can be sure won't otherwise appear is fine.
| sed -e 's/^$/###\n/' \
The reason for doing this is that groff always seems to pad its
output with a bunch of blank lines -- I haven't found a way to stop it doing
that when outputting plain text. We need to strip those blank lines, but
we don't want to strip the blank lines that we inserted earlier to
separate the different days. Marking the "real" blank lines with a
specific pattern will allow us to do that.
The groff invocation looks like this:
| groff -k -Tutf8 -man \
The Linux version of groff can not (so far as I know) handle
multi-byte input -- it assumes each character is a single byte. The BBC RSS
feed does produce multi-byte characters. In particular, there is the "degree"
sign, which isn't an ASCII character. The -k argument tells
groff to run a pre-processor that converts multi-byte
characters into groff formatting codes. Since most Linux
systems use UTF-8 character encoding, and the RSS format is UTF-8, no
other configuration is necessary to make this conversion.
The -Tutf8 switch allows UTF-8 output. -man
is an instruction to format in a way that is suitable for a Unix
man page; essentially, that means for output on a text terminal.
Tidying up
The final step is to remove the spare, empty lines added by groff,
and then convert the "real" empty lines we marked using the tag "###"
with real blank lines.
| sed '/^$/d' \ | sed 's/###/\n/g'
Further work
The simple script could be improved in many ways. Of course, the formatting of the output won't be to everybody's taste. It would be relatively easy to provide the script with command-line arguments so that you could select the forecast location, or change the amount of data that is displayed. The BBC also provides an RSS feed of current weather observations, rather than forecasts, and it could easily be parsed and formatted with the same approach -- and much of the same code -- I've described above.
Another, slightly useful enhancement would be to suppress the generation of terminal formatting characers if the output is not to a terminal.
Download
If you're interested, here is the Here is the complete source code for the script I've been describing in this post.
Have you posted something in response to this page?
Feel free to send a webmention
to notify me, giving the URL of the blog or page that refers to
this one.

