You be the linker -- building "Hello, world" from scratch, in hexadecimal

In this article I'm going to describe how to do something that is quite difficult, produces a trivial result, and has no practical benefit whatsoever. I'm going to explain how to produce a "Hello, world" program for Linux, from scratch, in hexadecimal. This is about the most low-level method of programming there is, unless we throw away the operating system and work on bare metal.
Why would anybody want to do such a thing? Well, there is no better way to understand how a program is structured, and how the operating system loads and runs it, than to build one in this most fundamental way.
To make life a bit easier, I'm going to focus on only one architecture: 64-bit Linux on AMD64 (x64) architecture. This is a fairly popular architecture and, in fact, there's little conceptual difference in the way any modern Linux system works. Of course, different CPUs will have different registers and different instruction codes, and I'm not even going to begin to discuss that. In addition, I'm not going to get into how to accommodate the different kinds of endianness, different segment alignments, etc., etc -- the job is difficult enough even for a single architecture.
To follow this exercise you don't need a compiler, or a linker, or
even a standard library. Yes, that's right -- the program's output will
be straight to the kernel. I will present and describe in detail
all the "source code", which is files full of hexadecimal numbers. You
should be able to cut-and-paste this into a file and convert it to binary
using the xxd utility but, to save time, all the necessary
files are on github.
Inputs and outputs
The input to the process will be a file, or many files, full of hexadecimal numbers in ASCII format. I'll include comments in the example but, of course, the comments won't contribute to the output. The output will be an executable program file in ELF format.
For simplicity, I've tried to implement the simplest
program I could think of -- it just writes "Hello, world" to
standard out -- and create the smallest, well-formed ELF file
I could come up with. In fact, Linux will load defective
ELF files, so long as the program code is correct and the header
specifies the correct memory mapping parameters. All the other stuff
is used by tools. So we should be able, for example, to
disassemble a valid ELF file using objdump. The kernel
is, in fact, more tolerant of a broken ELF file than most tools are,
but I wanted to create one that was actually complete, if minimal.
Structure of the minimal ELF executable
Our ELF executable needs the following components:
An ELF header. This is always the first thing in the file and, in a 64-bit binary, is always exactly 64 bits long. The ELF header is the only part of the ELF file with a fixed location -- the location of all the other parts of the file are set out in the ELF header.
One program header (more are allowed). This header indicates, among other things, how much of what part of the file needs to be loaded into memory.
A section for the compiled program code. Again, more are allowed, but we need only one. This section will be given the name
.textA string table section. This is not for program data, but to hold the names of the sections, including itself. Our string table will contain two entries:
.textfor the program code, and.shstrtabfor itself.Three section headers of 64 bytes in size. The first will be all zeros. This null header exists to allow for applications with huge numbers of sections, and is not relevant here. The section section header will define the location and size in the file of the
.textsection. The third defines the location and size of the string table.
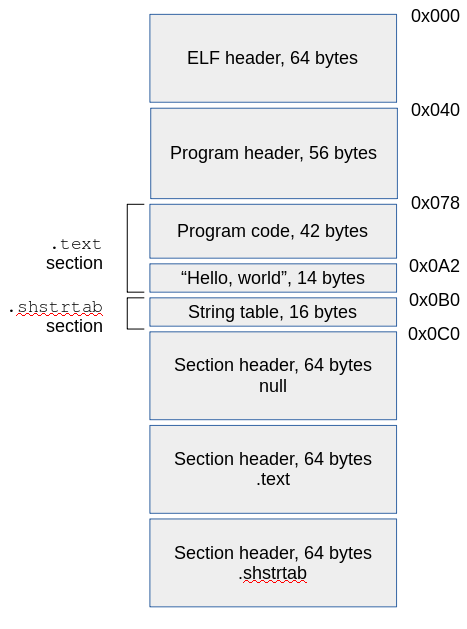
Building the executable file components in hexadecimal
In this section I describe how to write the hex codes for the various components of the executable file I outlined above. I will make frequent references to the offsets in the figure, and it will be difficult to follow the descriptions without having it handy.Calculating the sizes and offsets of the sections
Easy ones first: the ELF header, program header, and section headers are all of fixed size. I've put the program header directly after the ELF header, so it's offset is 0x40. I'm using hexadecimal numbers here, because these are what we need to poke into the file.
The compiled (that is, compiled by me) program code is 42 bytes long (keep reading to see why), and follows the program header, so it's at offset 0x78. The text "Hello, world" immediately follows the program code, so it's offset is 0xA2. It has a line feed and a terminating null (which isn't actually required here, but once a C programmer, always a C programmer). So it's size is 14 bytes. This puts the start of the string table, immediately after, at 0xB0.
The stringtable has two strings: .shstrtab and
.text. Both are terminated by zeros, so the total
size of this section is 9 + 1 + 5 + 1 = 16 bytes. The offset
into the table of the second string, .text is 10 bytes --
we'll need this information when setting up its section header.
Adding 16 to the offset of the start of the string table gives 0xC0 for the first section header. We don't need to know the offsets of the other section headers, because they are all the same size, and we will specify how many there are in the ELF header. Putting all these sizes together gives a total size of the ELF file of 384 bytes.
There's one more thing we need to know -- the amount of the file to load into memory. We need to load up to the start of the string table -- nothing else is needed at runtime. So we need to load 64 + 56 + 42 + 14 + 16 = 192 = 0xC0 bytes, starting from the beginning of the file.
A note on memory mapping
To write real applications (or a compiler for them) we need to know the memory mapping model in detail, that applies to our target architecture. For the present example, however, all we need to know is that the AMD64 architecture assumes that executable code will start at virtual address 0x400000 (4 MiB). There are a combination of technical and historical reasons for this. Essentially this address is one memory page up from zero, for the largest page size in common use.
We don't want anything useful in memory starting at 0x0 -- we want a null pointer genuinely not to point to anything.
Now, although the AMD64 architecture notionally has a 48-bit virtual address space, most instructions take only 32-bit direct operands (as we'll see in the program code later). Special techniques are needed to address memory beyond the 32-bit offset range. So we want to put the program code in the lowest virtual memory page as we can, other than the zero page.
Whatever the reason, we need to set the program header to load the relevant part of the binary file into memory starting at 0x400000. Because this will include the ELF header and program header, the program code that starts at offset 0x78 in the file will end up at 0x400078 in memory.
0x400078 is such a common starting address that the GNU linker ld
assumes it by default, if you don't specify a symbol called
_start. Of course, we aren't using a linker here --
we are the linker; so we have to specify this address correctly.
Building the ELF header
We now have all the information we need to populate the ELF header: we know what all the relevant offsets are, and we know where to load the binary data, and how much. We know that there will be three section headers, and that entry 2 contains the string table.
The ELF header is well documented, so I don't propose to describe what every entry does. I've put comments in the hex data below to explain the various settings but, of course, the comments will never form part of the executable file -- we'll have to strip them out.
# ELF header -- always 64 bytes # Magic number 7f 45 4c 46 # 02 = 64 bit 02 # 01 = little-endian 01 # 01 = ELF version 01 # 00 = Target ABI -- usually left at zero for static executables 00 # 00 = Target ABI version -- usually left at zero for static executables 00 # 7 bytes undefined 00 00 00 00 00 00 00 # 02 = executable binary 02 00 # 3E = amd64 architecture 3e 00 # 1 = ELF version 01 00 00 00 # 0x400078 = start address: right after this header and the program # header, which take 0x78 bytes, if the binary is mapped into # memory at address 0x400000) 78 00 40 00 00 00 00 00 # 0x40 = offset to program header, right after this header which is 0x40 bytes long 40 00 00 00 00 00 00 00 # 0xC0 = offset to section header, which is after the program text and the # string table c0 00 00 00 00 00 00 00 # 0x00000000 = architecture specific flags 00 00 00 00 # 0x40 = size of this header, always 64 bytes 40 00 # 0x38 = size of a program header, always 56 bytes 38 00 # 1 = number of program header 01 00 # 0x40 = size of a section header, always 64 bytes 40 00 # 3 = number of sections headers 03 00 # 2 = index of the section header that references the string table 02 00
Constructing the program header
We also have enough information to construct the program header. Note that it replicates some of the information already provided in the ELF header. Again, I've put comments to explain how the various settings are derived in this example, but I don't want to explain every one.
# Program header -- always 56 bytes # 1 = type of entry: loadable segment 01 00 00 00 # 0x05 = segment-dependent flags: executable | readable 05 00 00 00 # 0x0 = Offset within file 00 00 00 00 00 00 00 00 # 0x400000 = load position in virtual memory 00 00 40 00 00 00 00 00 # 0x400000 = load position in physical memory 00 00 40 00 00 00 00 00 # 0xB0 = size of the loaded section the file B0 00 00 00 00 00 00 00 # 0xB0 = size of the loaded section in memory B0 00 00 00 00 00 00 00 # 0x200000 = alignment boundary for sections 00 00 20 00 00 00 00 00
"Compiling" the program
The program will do two things:
Print "Hello, world" to standard out.
Exit.
With high-level languages we don't necessarily think of "exit" as a compulsory operation -- the program typically stops when it runs out of things to do. In machine language, though, we always need a specific exit operation.
Both the print and the exit are achieved by 'syscalls', that is, calls into the kernel. The AMD64 syscalls are not as well-documented as they should be -- except in the kernel source. For reference I usually look at this article by Ryan Chapman.
The way syscalls work is fairly straightforward -- load the
syscall number into the %rax register, load the arguments into
various other registers (all documented in the previous link), and
then execute the syscall function.
For our application we need just two syscalls: sys_write (1)
nd exit (60).
mov $1, %rax # sys_write
mov $1, %rdi # file descriptor, 1=stdout
mov $hello, %rsi # buffer
mov $13, %rdx # byte count
syscall
mov $60, %rax # exit
xor %rdi, %rdi # return value, 0
syscall
But wait -- all the values being put into registers are literals,
except $hello. This is where we get to play "you be
the linker". Lacking a linker we need to replace the value of
$hello with the (32-bit) memory address of the
string "Hello, world". You'll remember that I decided to put
this string directly after the program code. The program code
will turn out to be be 42 bytes long, and it starts at
0x40078. The location of the string is therefore 0x40078 + 82,
or 0x4000A2. We'll need to insert this manually into the
hexadecimal code at the appropriate position.
There are two ways to go about turning the assembly code into real, hexadecimal machine instructions. The first is to spend a great deal of time studying x86 reference material and other documents. The second is to cheat, and use a real assembler for this part. The choice is yours ;) If you grew up with 8-bit microprocessors as I did, you'll find that the enormous, convoluted instruction set of AMD64 devices is quite painful to work with. Of course, until in the 8-bit days, modern CPUs are not designed to be human-readable.
However you achieve the assembly process, the program code, followed by the text string, looks like this:
# Program code -- 42 bytes # mov 0x01,%rax -- sys_write 48 c7 c0 01 00 00 00 # mov 0x01,%rdi -- file descriptor, stdout 48 c7 c7 01 00 00 00 # mov 0x4000a2,%rsi -- location of string (see text above) 48 c7 c6 a2 00 40 00 # mov 0x0d,%rdx -- size of string, 13 bytes 48 c7 c2 0d 00 00 00 # syscall 0f 05 # mov 0x3c,$rax -- exit program 48 c7 c0 3c 00 00 00 # xor %rdi,%rdi -- exit code, 0 48 31 ff # syscall 0f 05 # Text "Hello, world\n\0" -- total 14 bytes including the null 48 65 6c 6c 6f 2c 20 77 6f 72 6c 64 0a 00
Constructing the string table
This, at least, is dead easy. It's just the ASCII values for
the two strings .shstrtab and .text,
null terminated, one after the other. Here it is:
# String table. ".shstrab\0.text\0" -- 16 bytes 2e 73 68 73 74 72 74 61 62 00 2e 74 65 78 74 00
Constructing the section header table
As I described above, there are three section headers, all 64-bits. The first one is easy -- it's all zeros. The next section header describes the.text section, and looks like this:
# Section header table, section 1 -- program text -- 64 bytes # 0x0A = offset to the name of the section in the string table 0a 00 00 00 # 1 = type: program data 01 00 00 00 # 0x06 flags = executable | occupies memory 06 00 00 00 00 00 00 00 # 0x400078 address in virtual memory of this section 78 00 40 00 00 00 00 00 # 0x78 = offset in the file of this section (start of program code) 78 00 00 00 00 00 00 00 # 0x38 = size of this section in the file: 56 bytes 38 00 00 00 00 00 00 00 # sh_link -- not used for this section 00 00 00 00 00 00 00 00 # 0x01 = alignment code: default?? 01 00 00 00 00 00 00 00 # sh_entsize: not used 00 00 00 00 00 00 00 00
Note that the section header describes where the section is located in the file, how large it is, and where it is to be loaded into memory.
Here's the section header for the string table:# Section header table, section 2 -- string table # 0x0 = offset to the name of the section in the string table 00 00 00 00 # 3 = type: string table 03 00 00 00 # 0x0 = flags 00 00 00 00 00 00 00 00 # 0x0 = address in virtual memory (not used) 00 00 00 00 00 00 00 00 # 0xB0 = offset in the file of this section (start of string table) b0 00 00 00 00 00 00 00 # 0x10 = size of this section in the file: 16 bytes 10 00 00 00 00 00 00 00 # sh_link -- not used for this section 00 00 00 00 00 00 00 00 # 0x01 = alignment code: default?? 01 00 00 00 00 00 00 00 # sh_entsize: not used 00 00 00 00 00 00 00 00
Note that there is no memory address in this section -- it will never be loaded into memory.
Putting it all together
That's the hard part done. At this stage, we have a number of files of somewhat incomprehensible hexadecimal text or, perhaps, one large, totally incomprehensible one.
We can use the standard xxd utility to convert these
hex files to binary, but we'll need to strip the comments first.
Here is the script I use to build the executable file from my
hex files:
BINARY=elfdemo cat 0_elf_header.hex \ 1_program_header.hex \ 2_program_code.hex \ 3_string_table.hex \ 4_section_header_0.hex \ 5_section_header_1.hex \ 6_section_header_2.hex \ | grep -v "#" > $$.hex xxd -p -r $$.hex $BINARY chmod 755 $BINARY rm $$.hex
This script just concatenates all the individual hex files into one
large file, strips the comments, and passes the result to xxd
to turn into binary. If all is well, the resulting elfdemo
will be 384 bytes long, and if you run it, you'll see:
$ ./elfdemo Hello, world
Have you posted something in response to this page?
Feel free to send a webmention
to notify me, giving the URL of the blog or page that refers to
this one.

